![]()
![]() High
Availability Kozepte
High
Availability Kozepte ![]()
Ziele und Abgrenzungen
Von High Availability (HA) spricht man wenn ein System nach einem Ausfall automatisch auf einem anderen (Ausfall-System) weiterlaufen soll. Es stehen verschiedene Möglichkeiten, je nach Anforderung zur Verfügung. Bewusst wird in der folgenden Zusammenstellung nicht auf die Ausfallsicherheit von Platten (Disk-Arrays) mit den entsprechenden RAID-Levels eingegangen.
Grundsätzlich stehen folgende Möglichkeiten zur Verfügung
|
Backup Tape Shipping
Tape wird auf einem Ausfallsystem nach einem Ausfall des produktiven System eingelesen. Das Failover-System muss gleich vorkonfiguriert sein wie das Produktivsystem.

|
Vorteile |
|
|
Nachteile |
|
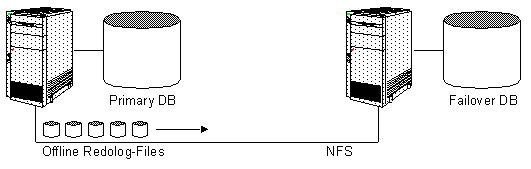
Standby Database
Eine Standby Database wird mit den offline Redologs laufend oder bei Bedarf aktuell gehalten. Die offline Redolog-Files werden via Tape oder über NFS zur Failover Datenbank geschickt.
|
Vorteile |
|
|
Nachteile |
|
Proprietäre Systeme
Proprietäre Systemen wie HP-Service-Guard oder VERITAS-AXXiON ist gemeinsam, dass die Failover-Datenbank auf den Secondary-Host «gezügelt» werden. Es erfolgt also in jedem Fall ein Shutdown der Datenbank.

|
Vorteile |
|
|
Nachteile |
|
Proprietäre Systeme eignen sich hervorragend für Application-Failover‘s, aber weniger für echte DB-Failover, da in jedem Fall die Datenbank auf dem Secondary Host neu gestartet werden muss.
Weitere Informationen: http://www.veritas.com
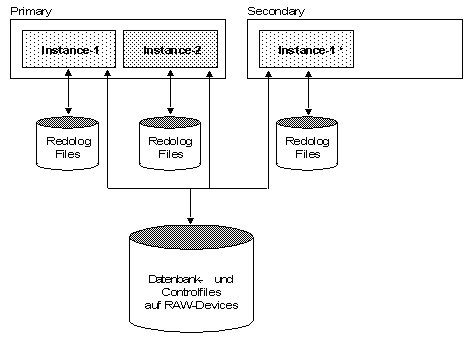
Oracle Parallel Server
Oracle Parallel Server und Multimaster Replication stellen eine gleichzeitig verfügbare gespiegelte DB-Instanz zur Verfügung, sie bieten also die grösste Ausfallsicherheit an. Das Ziel des Oracle Parallel Servers ist nebst der HA-Komponente die parallele Verarbeitung von Daten. Dies kann jedoch nur bei gut parallisierten Applikationen genutzt werden, ansonsten kann die Performance sogar schlechter werden. Dies inbesondere dann, wenn mehrere DB-Instanzen die gleichen DB-Blocks verändern müssen. Oracle Parallel Server zeichnet sich durch folgende Merkmale aus:
|
Vorteile |
|
|
Nachteile |
|
Multimaster Replikation
Multimaster Replikationen sichern auch ein Site-Failure ab (Feuer, Wasser, Zerstörung, etc). Alle DB-Änderungen werden asynchron auf die andere Master-Site transferiert. UPDATES sind auf allen Knoten möglich.

|
Vorteile |
|
|
Nachteile |
|